Wasserstein 距离
对于绝大多数的机器学习问题,尤其是预测问题和隐变量模型(latent factor model)中,学习到数据集背后所服从的分布往往是模型所要解决的最终问题。在变分推断(variational inference)等领域中,往往会先从一个简单的分布引入,比如高斯分布或者多项式分布等;希望由这个简单的分布模型能不断学习进而逼近最终想要的、符合数据背后规律的分布,注意这时候的分布往往可能在形状上与初始假设的分布有所差异。
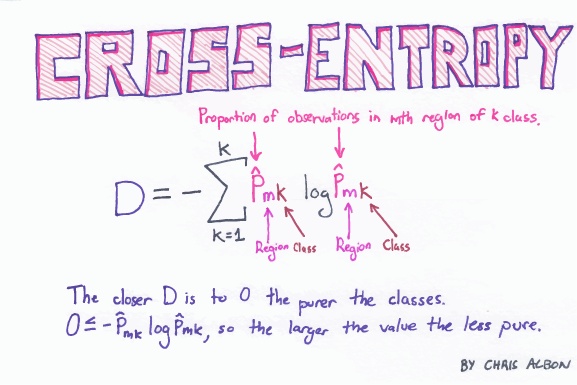
KL散度和JS散度
在学习Wasserstein距离,首先回顾在机器学习算法中,衡量两个分布相似程度的指标常常是KL散度(Kullback-Leibler Divergence)以及JS散度 (Jensen-Shannon Divergence)。
KL散度
KL散度描述的是,评价训练所得的概率分布p与目标分布q之间的距离,可以表示为:
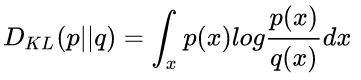
机器学习的算法最终的目的是缩小 $D _ {KL}$ 的值,可以看到当 $p(x)==q(x)$ 的时候,KL散度处处为0,达到最优结果。 但同时必须注意的是,由于KL散度中,对数项中$p(x)$与$q(x)$相对位置的关系,决定了KL散度其实是非对称的,即 $D_{KL}(p||q) \neq D_{KL}(q||p)$ .从物理学参考系的角度可以直观感受出,如果要想评价两个物体(分布)的相似程度,相似程度的值(比如KL散度)应该不能因为选取的参考目标(目标分布)的不同而改变。
JS散度
既然KL散度不具备对称性,那么依然从参考系的角度出发,那我们直接把所有参考系下计算的距离平均即可(在本文环境下只有目标分布和预测分布两个参考系)。这样便是JS散度的思想,具体的定义为:
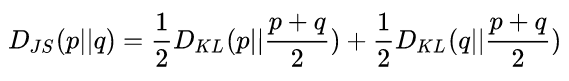
因而JS散度便有了对称性,并且形式上更为平滑,更适合作为最后最大似然的函数,这点在生成对抗网络(GAN)的损失函数取得了不错的成绩。
Wasserstein距离
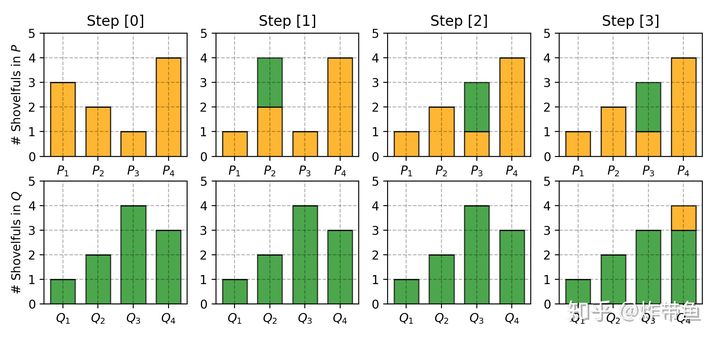
Wasserstein距离也叫做推土机距离(Earth Mover’s distance),这也是由于它的推导过程可以很形象的用挖土填土来解释,这也是因为该距离定义中由一个分布转变为另一个分布所需要的代价和挖土填土的过程十分相似。考虑两个离散的分布P和Q:
P1 = 3, P2 = 2, P3 = 1, P4 = 4
Q1 = 1, Q2 = 2, Q3 = 4, Q4 = 3
为了让两个分布相同,我们一个个变量地观察,
- 为了让P1和Q1相同,我们需要P1把手头上的3分2到P2去,这样P1和Q1都等于1,此时P2=4,其他数保持不变,这个过程是不是非常像挖掉P1的土填到P2上
- 为了让P2和Q2相同,我们也要做类似的挖土填土工作,但注意,此时P2手头上由P1填的2,因此现在P2是4,但是Q2依然是2,因而P2也要挖2分土给P3,保持和Q2一样。
- P3和Q3也是一样,但此时P3为3,Q3为4,因为我们只能先挖土再填土,因此要Q3挖1分土给Q4,这样P4和Q4也能够一样。
每一步的代价计算公式为$\delta_{i+1} = \delta_{i} + P_{i} -Q_i$,第0步我们规定为0,故有
$\delta_{0} = 0$
$\delta_{1} = 0+3-1 = 2$
$\delta_{2} = 2+2-2 = 2$
$\delta_{3} = 2+1-4 = -1$
$\delta_{4} = -1+4-3 = 0$
所以最终的总代价,也即Wasserstein距离则为$W=\sum_i |\delta_i|=5$
该挖土填土的过程可以由下图表示:(图片来源:From GAN to WGAN)
由离散情况理解了距离计算以后,针对一般的连续分布,Wasserstein距离则变成如下形式:
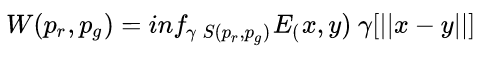
其中inf指代最大下界,$S(p_r,p_g)$表示的是分布$p_r$和$p_g$中所有可能的联合分布,每一个联合分布$\gamma \in S(p_r,p_g)$都是之前提到的“土”,用于刻画连续空间中分布间转换的代价,更具体而言,$\gamma(x,y)$刻画从x点转移到y点从而让x,y服从相同分布所需要的“土”的百分比。因此$\gamma$的边缘分布可以表示为$\sum_x \gamma(x,y)=p_g(y),\sum_y \gamma(x,y)=p_r(x)$
当我们将x作为我们的起始点,y作为我们要逼近的终点时,挖土填土的总量即为$\gamma(x,y)$,也即上文离散情况下计算的代价$\delta$,而点与点之间的距离则为||x-y||,因而总代价为$\sum_{x,y} \gamma(x,y)||x-y||$,总代价最后可以使用EM等方法求得最小值。
为什么Wasserstein距离优于KL和JS散度
P,Q两个分布完全重合,此时这三种距离度量方式均为0。可以看出KL散度在两个分布完全没有任何交集的时候会得出无穷的结果,而JS散度则会有突然的阶跃,并且在0点出不可微,只有Wasserstein距离能够提供更为平滑的结果用于梯度下降法的参数更新。不过值得一提的是,目前主流的分布距离度量依然是KL散度,这是由于KL散度的计算方式简单,计算成本较Wasserstein低,但近年来Wasserstein距离的近似Sinkhorn distance以及其他加快距离计算方法的论文也在不断涌现.