PS:参考YOLO官网的配色和logo做的封面图,感觉还挺好看的,hhhh
1. 论文信息
论文标题:You Only Look Once: Unified, Real-Time Object Detection
论文发表:CVPR 2016
论文链接:You Only Look Once: Unified, Real-Time Object Detection (cv-foundation.org)
论文官网:YOLO: Real-Time Object Detection (pjreddie.com)
.png)
1 | @inproceedings{redmon2016you, |
2. 归纳总结
| 标签 | 目的 | 方法 | 总结 |
|---|---|---|---|
| #Anchor-Free | 解决两阶段算法检测慢的问题 | 将目标检测(cls和reg)都视为回归问题 | 经典单阶段算法 |
3. 问题背景
随着深度学习的大火,在YOLO提出那一年,主流的目标检测算法框架主要分为两类:
- 两阶段算法:基于Region Proposal的RCNN系列算法,先生成Proposal,再分类回归
- 单阶段算法:直接预测不同目标的类别和位置
这两种算法各有优点,一般而言,两阶段算法准确度高,但速度慢;单阶段算法速度快,但准确度相对低。
作者认为人可以一眼看到目标在哪,并且能立即知道是什么,并且对于很多实际场景而言,如自动驾驶,实时性和准确性都是非常重要的。
4. 主要工作
针对上述问题,作者提出了经典的YOLO算法,它是一个统一的,端到端的单阶段目标检测算法。YOLO具体做法是,首先将输入图片缩放到448x448,然后送入CNN网络,最后使用NMS过滤网络预测结果得到检测的目标。

而在CNN网络里,它首先将图片划分为S×S大小的网格,然后每个单元格负责检测中心点落在该格子的目标,如下图,每个单元格会输出B个边界框(每个边界框输出5个预测值:x, y, w, h, confidence)以及边界框类别概率C,例如:作者在PASCAL VOC的检测实验里使用S=7,B=2,C=类别数量20,一共预测7×7×(2×5+20)个向量。同时这里的confidence代表边界框置信度,它的定义为:
$$Pr(object)\times IoU_{pred}^{truth}$$
其中边界框包含目标时,$Pr(object)=1$,否则为0。而C代表每个类别的置信度,即:
$$Pr(Class_i|Object)\times Pr(objec) \times IoU_{pred}^{truth}=Pr(class_i)\times IoU_{pred}^{truth}$$

4.1 模型结构
YOLO采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数$max(x,0.1x)$,但是最后一层却采用线性激活函数。

4.2 模型训练
在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用图8中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。
4.3 模型损失
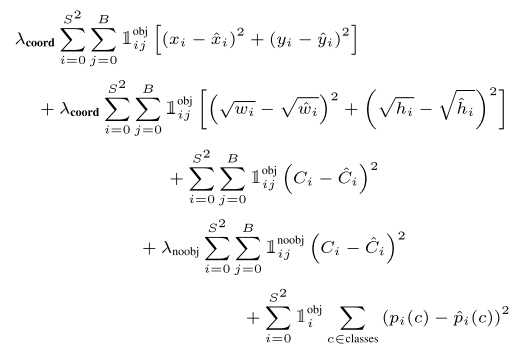
Yolo算法将目标检测看成回归问题,所以采用的是均方差损失函数。但是对不同的部分采用了不同的权重值。首先区分定位误差和分类误差。对于定位误差,即边界框坐标预测误差,采用较大的权重 $\lambda_{coord}=5$ 。然后其区分不包含目标的边界框与含有目标的边界框的置信度,对于前者,采用较小的权重值 $\lambda_{noobj}=0.5$ 。其它权重值均设为1。然后采用均方误差,其同等对待大小不同的边界框,但是实际上较小的边界框的坐标误差应该要比较大的边界框要更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测,即预测值变为$(x,y,\sqrt{w},\sqrt{h})$。
损失函数中,第一项为边界框中心坐标的误差项,$\mathbb{1} _ {ij}^{obj}$ 是指第 i 个单元格存在目标,且该单元格中的第 j 个边界框负责预测该目标,第二项是边界框的高与宽的误差项。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。最后一项是包含目标的单元格的分类误差项,$\mathbb{1} _ {i}^{obj}$值是指第 i 个单元格存在目标。
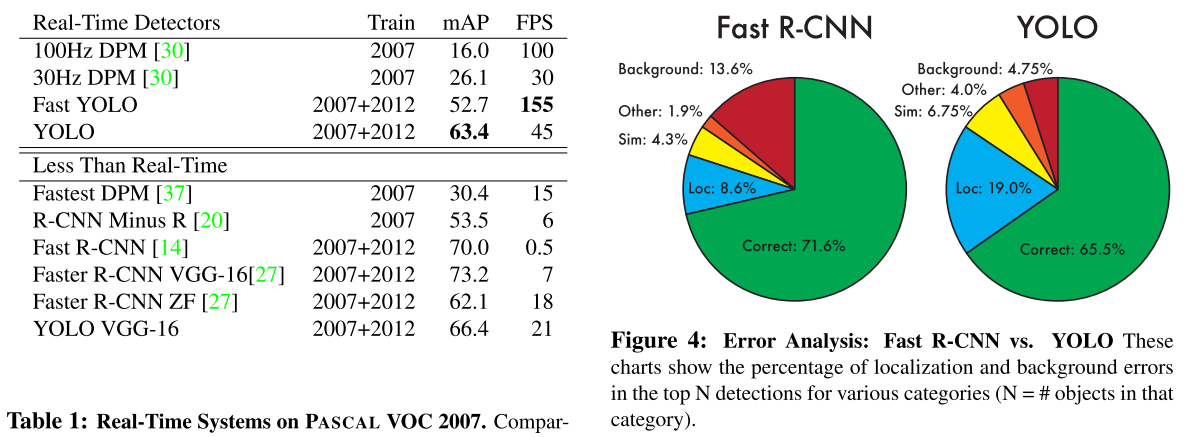
5. 实验结果