小样本学习
人类非常擅长通过极少量的样本识别一个新物体,比如小孩子只需要书中的一些图片就可以认识什么是“斑马”,什么是“犀牛”。在人类的快速学习能力的启发下,研究人员希望机器学习模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,这就是 Few-shot Learning 要解决的问题。Few-shot learning (FSL) 在机器学习领域具有重大意义和挑战性,是否拥有从少量样本中学习和概括的能力,是将人工智能和人类智能进行区分的明显分界点,因为人类可以仅通过一个或几个示例就可以轻松地建立对新事物的认知,而机器学习算法通常需要成千上万个有监督样本来保证其泛化能力。
1.基础概念
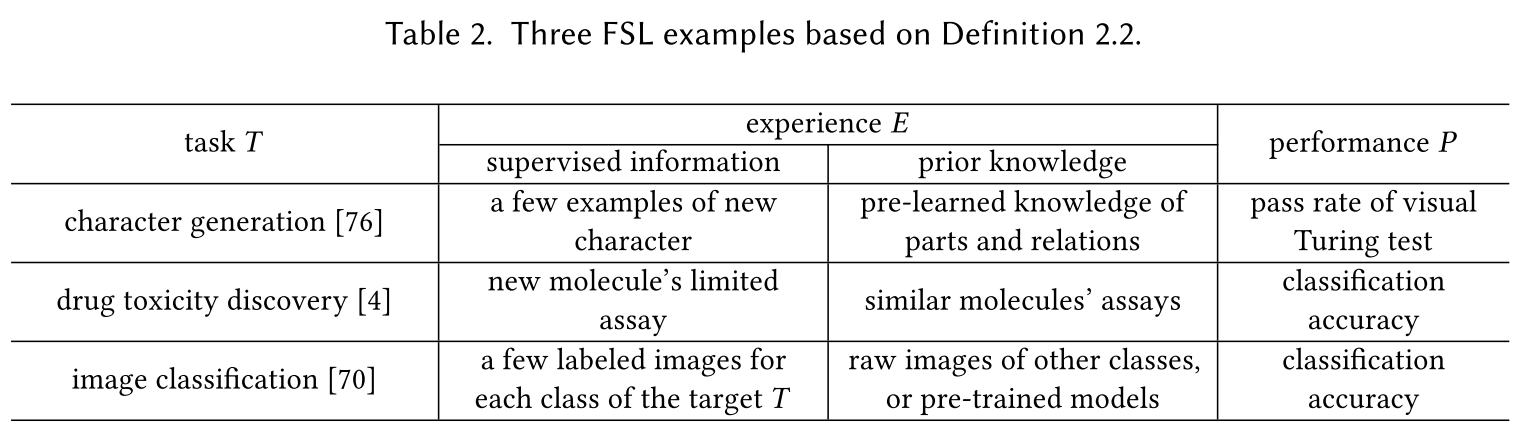
机器学习定义:A computer program is said to learn from experience E with respect to some classes of task T and performance measure P if its performance can improve with E on T measured by P.

小样本学习定义:Few-Shot Learning (FSL) is a type of machine learning problems (specified by E, T and P), where E contains only a limited number of examples with supervised information for the target T.
小样本学习(Few-shot learning),或者称为少样本学习(Low-shot learning),包含了n-shot learning,其中n代表样本数量,n=1的情况下,也被称One-shot learning,而n=0的情况下,被称为Zero-shot learning。

小样本学习的主要思想是利用先验知识使其快速适用于只包含少量带有监督信息的样本的任务中。
2. 方法分类
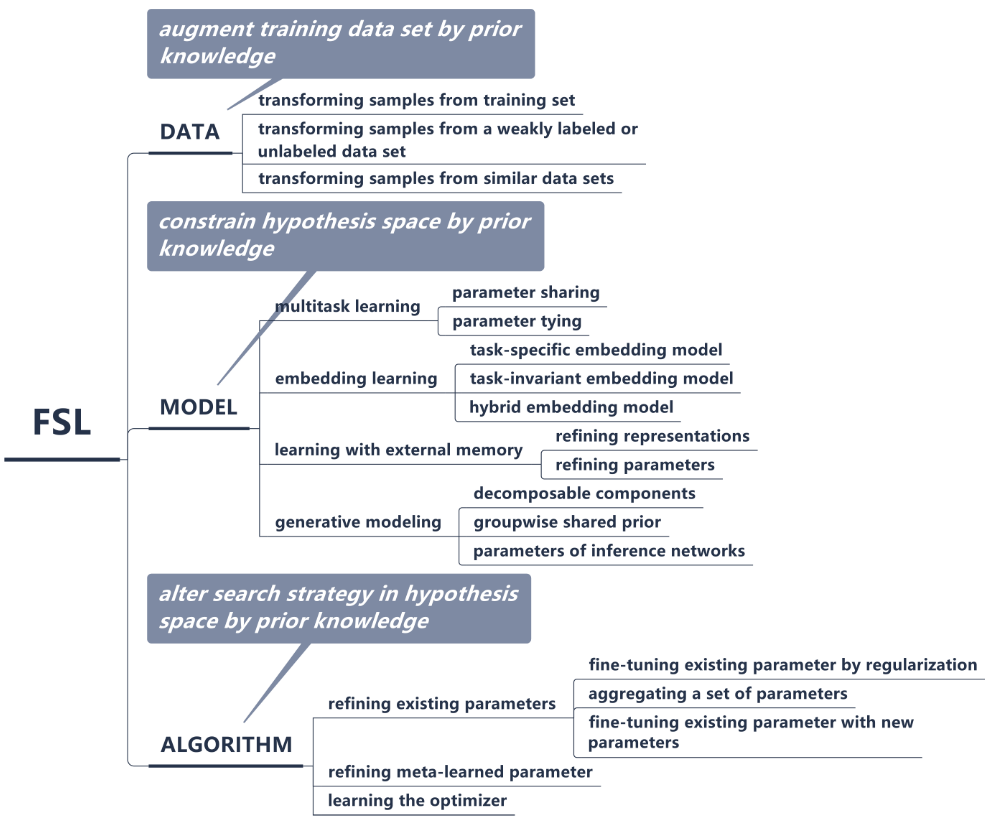
小样本学习问题的解决方法可以根据先验知识的利用方式分为三类:
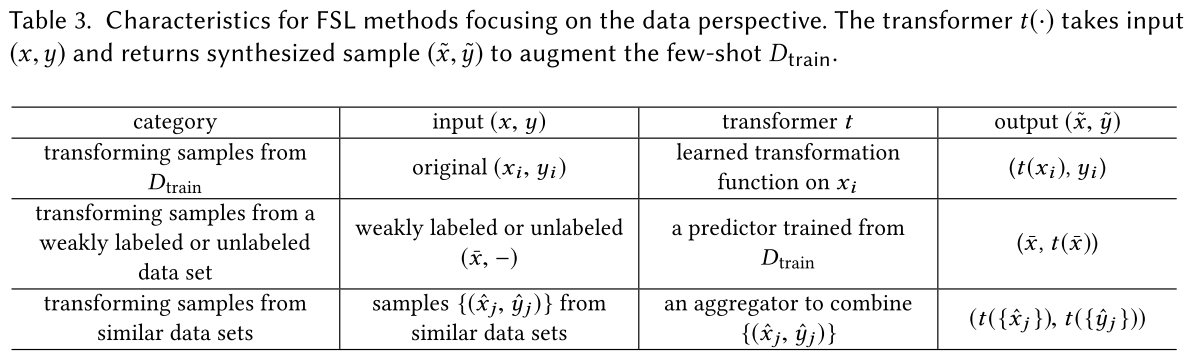
- 数据:此类方法利用先验知识来增强训练数据集或者增加样本数量(从样本量的角度)

- 1.使用旋转,翻转,裁剪等方法对训练集图像增强
- 2.从其他数据集获取图像用于扩充训练集
- 3.使用GAN来生成具有相似分布的数据用于扩充训练集
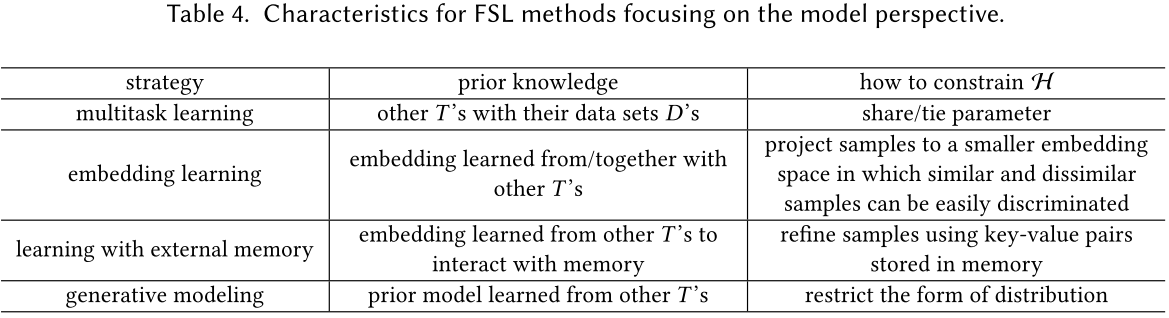
- 模型:此类方法利用先验知识来限制假设空间的复杂性(从模型训练的角度)
- 1.多任务学习(同时进行多个相关任务训练,共享表示,以获得更好的泛化能力)与迁移学习不同(将源任务中学到的知识运用到目标任务中)
- parameter sharing:多任务间共享参数(例如最开始几层网络结构共享,最后输出层单独训练)
- parameter typing:对不同任务的参数正则化处理,使其参数相似(encourages parameters of different tasks to be similar using regularization)
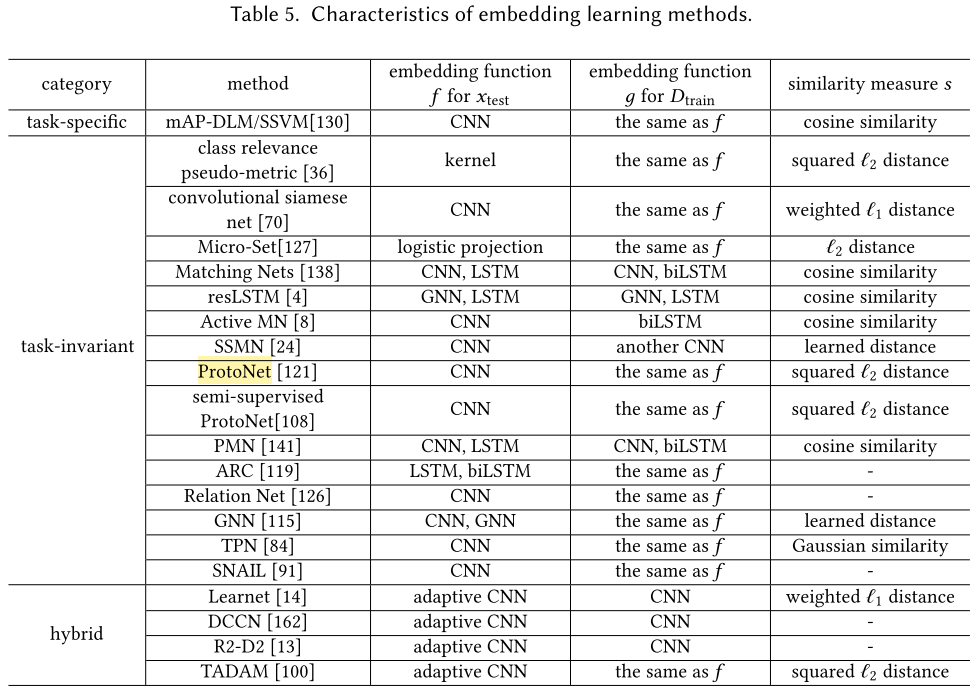
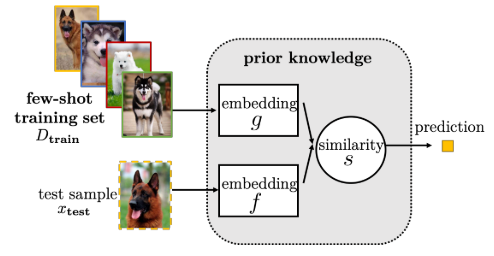
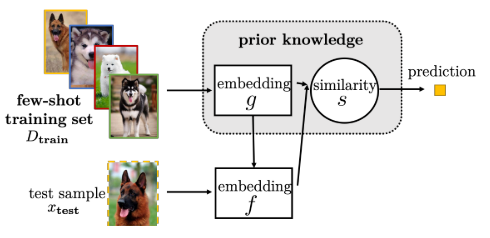
- 2.嵌入学习(将样本映射(嵌入)到低纬度空间后,相似样本距离更近,不相似样本距离远)
- Task-Specific Embedding Model:只使用来自任务的信息学习一个定制的嵌入函数
- Task-Invariant Embedding Model:将从其他充足样本中学到的信息直接利用到小样本学习任务中
- Matching Nets
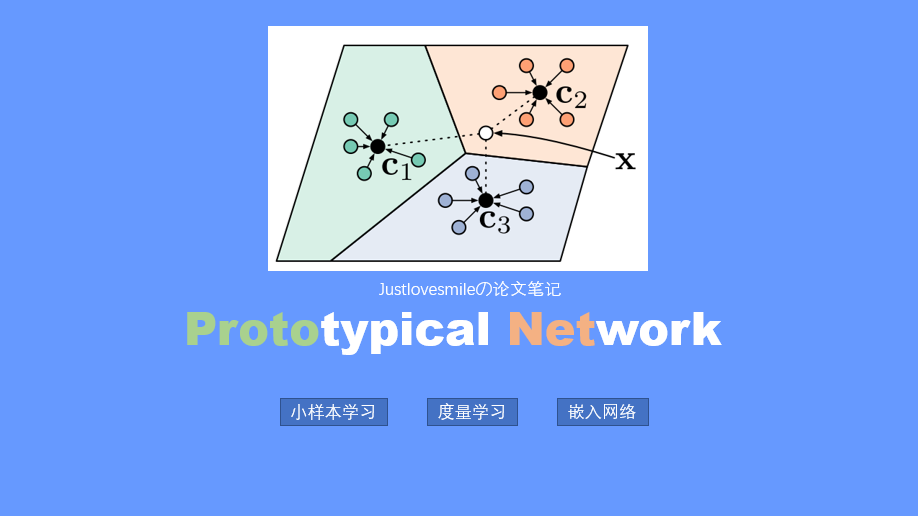
- Prototypical Networks(ProtoNet)
- Hybrid Embedding Model: 前两种方法的结合,使用小样本任务中的task specific信息运用到从先验知识学到的task invariant嵌入模型
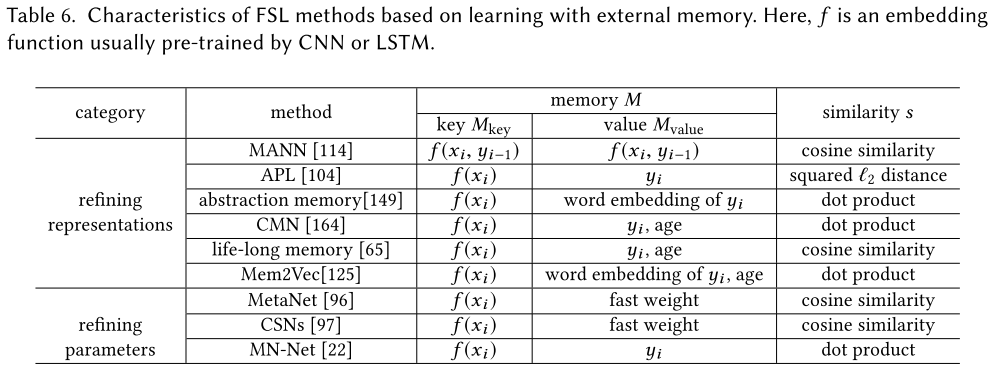
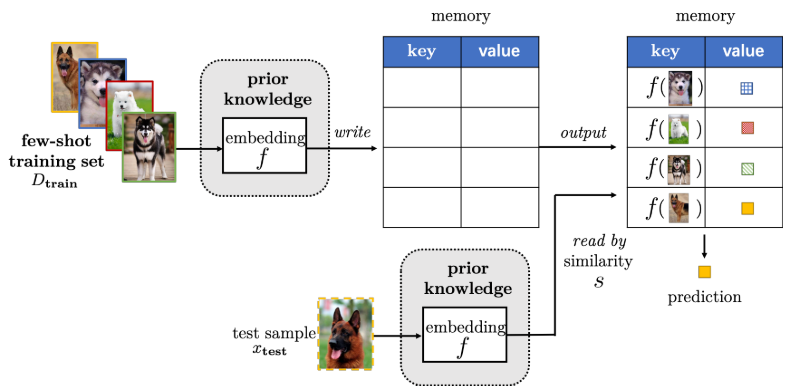
- 3.带有存储的模型,构建键值存储,并优化内存,每个新样本都可以由内存中提取出的内容的加权平均值表示(通过查询相似性),进一步限制假设空间。
- 优化表征(representation)
- 优化参数(parameter)
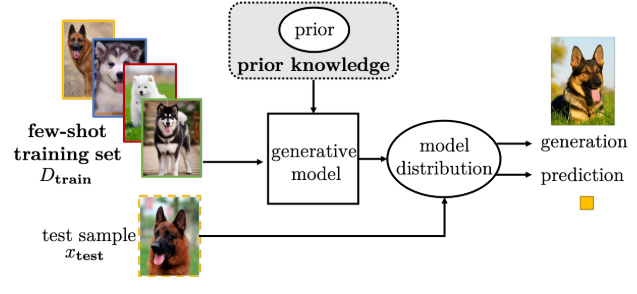
- 4.生成模型,对于样本x在先验知识的帮助下可以估计其分布p(x):假设x的分布可以表示为受$\theta$约束的$p(x;\theta)$,并且通常还存在潜在变量$z \sim p(z;y)$,因此$x \sim \int p(x|z;\theta)p(z;y)dz$,即在先验分布$p(z;y)$的帮助下,可以进一步缩小假设空间的大小.
- Decomposable Components:训练可分解组件模型,在不同任务间共享分解组件的信息,最后再找到分解组件的组合方式(模型层面?)
- Groupwise Shared Prior:使用无监督学习将数据集分组,对于新类别,首先查询其所属组,再根据其所属组的先验概率建模(相似的任务拥有相似的先验概率)
- Parameters of Inference Networks:找到最佳的$\theta$,使得最大化$p(z|x;\theta,\gamma)=\frac{p(x,z;\theta,\gamma)}{p(x;\gamma)}=\frac{p(x|z;\theta)p(z;\gamma)}{\int p(x|z;\theta)p(z;\gamma)dz}$,通常使用从数据中学到的变分分布$q(z;\delta)$来估计$p(z|x;\theta,\gamma)$。(?)
- 算法:此类方法利用先验知识在假设空间中搜索最优的假设
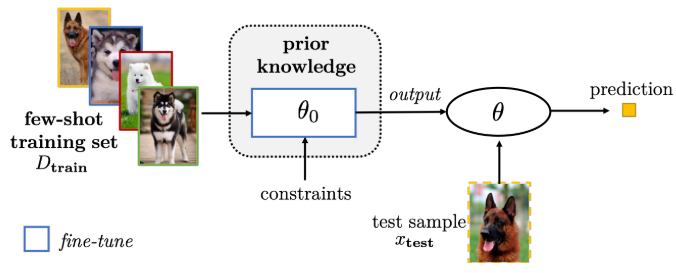
- 1.精炼现存参数
- 使用预训练模型,通过正则化进行微调
- Early-stopping
- Selectively updating parameters
- Updating related parts of parameters together
- Using a model regression network
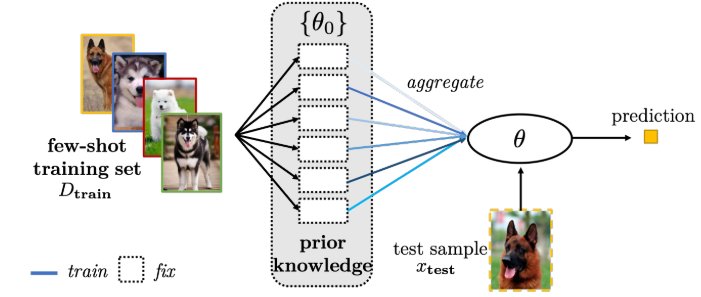
- 聚集子任务的参数(参数层面?)
- 使用新参数微调现有参数:给模型参数扩充一个$\delta$,使其参数为$\theta={\theta_0,\delta}$,然后通过学习$\delta$来微调初始参数$\theta_0$。
- 使用预训练模型,通过正则化进行微调
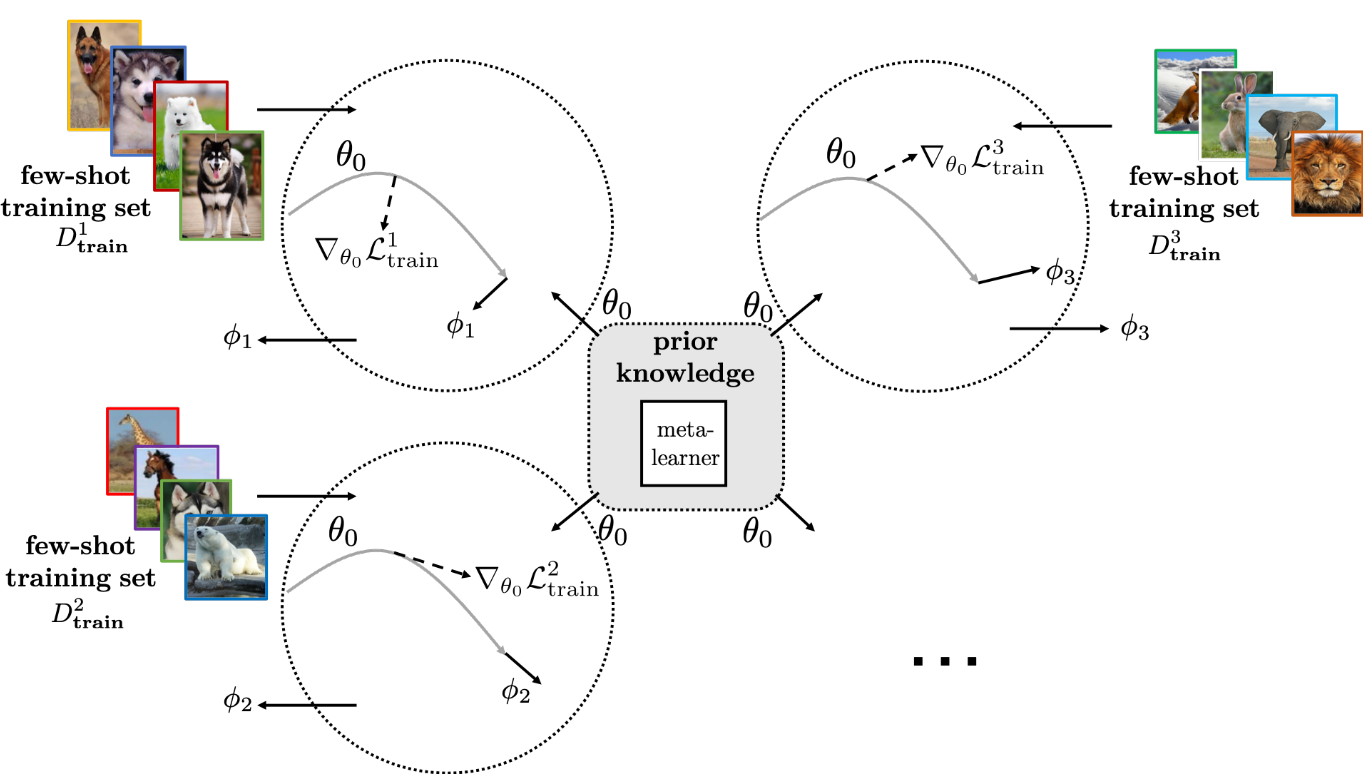
- 2.精炼Meta-Learned参数
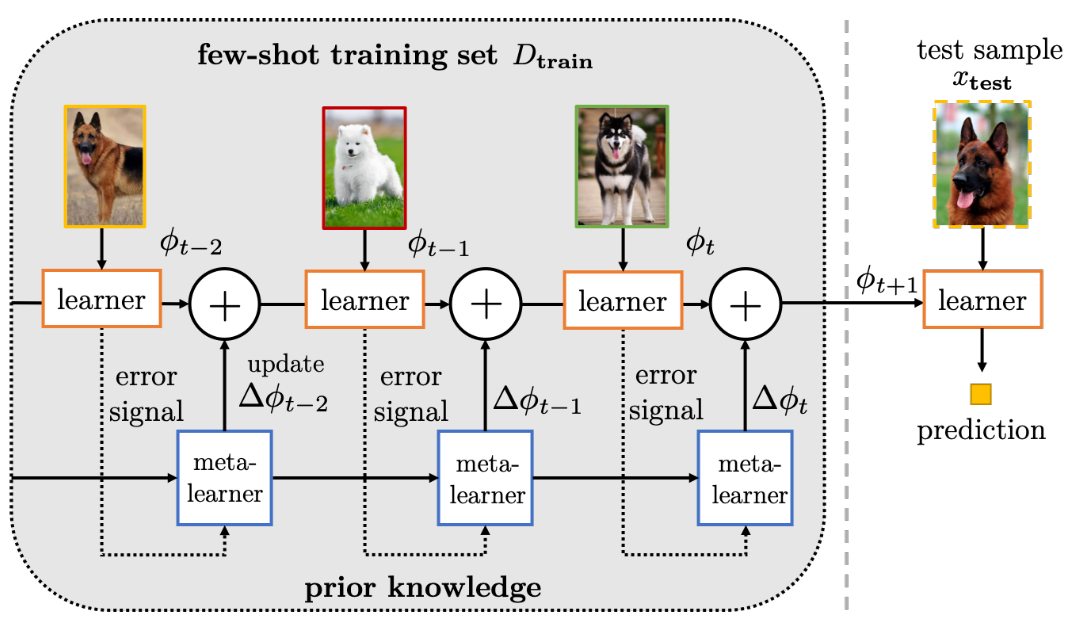
- 3.学习优化器:不使用梯度下降来更新参数,而是通过学习一个优化器来输出参数的更新,即$\Delta{\theta^{i-1}}$

3. 小样本学习常用数据集
小样本常用Benchmark图像数据集:
- Omniglot
- Mini-Imagenet
- CU-Birds